")
For years, transaction monitoring has operated on a delayed logic. Transactions were processed, alerts were generated in batches, and risk teams reviewed cases hours or even days later. That model made sense when payments moved slowly and reversibility was assumed. In 2026, it no longer reflects how money actually flows.
Real-time payment rails have fundamentally changed the risk landscape. Instant transfers, faster settlements, and always-available payment channels compress the window between action and outcome to seconds. In that environment, monitoring that relies on overnight files or scheduled alert runs is no longer just inefficient, it is misaligned with reality. By the time a batch alert is reviewed, the funds have already moved, and the opportunity to intervene has passed.
The challenge is not simply speed. Batch monitoring also amplifies false positives. Static thresholds and delayed context force systems to flag transactions without understanding how behaviour unfolds in real time. Legitimate users are repeatedly escalated, while genuinely risky patterns are detected too late. As volumes grow, this creates a paradox: more alerts, less actionable insight.
Always-on transaction monitoring represents a structural shift rather than a tooling upgrade. Instead of asking whether a completed transaction looks suspicious, streaming models continuously evaluate events as they occur logins, device changes, behavioural shifts, payment attempts and make decisions in context. Risk becomes something that is assessed during the journey, not after it.This shift aligns closely with the risk-based principles that underpin modern AML and financial crime frameworks. International guidance increasingly emphasises continuous assessment, proportional controls, and the use of data-driven signals rather than static rules. The foundation for this thinking is set out in work published by the Financial Action Task Force, which frames monitoring as an ongoing process that must adapt to speed, scale, and evolving risk patterns.
- Streaming TM Fundamentals: Event Pipelines, Features, and Entity Resolution
- Automation Layers: Alert Suppression, Clustering, Typology Tagging, and Enrichment
- Reducing False Positives Safely: Risk-Based Thresholds and Feedback Loops
- Signals That Matter in 2026: Why Context Beats Volume
- How to Operationalise Outcomes: Auto-Close Rules, QA Sampling, and Escalation Criteria
- Governance: Model Drift, Periodic Tuning, Explainability, and Documentation
- KPIs: Alert-to-Case Ratio, Analyst Hours per 1k Transactions, True-Positive Yield, Time-to-File
- Conclusion
- FAQs
Streaming TM Fundamentals: Event Pipelines, Features, and Entity Resolution
From transactions to events
Traditional transaction monitoring was built around a simple unit of analysis: the completed transaction. Streaming monitoring changes that perspective entirely. Instead of waiting for a payment to finish and then evaluating it in isolation, always-on systems observe a continuous stream of events that together form a risk narrative.
These events include logins, device changes, failed attempts, behavioural shifts, payment initiations, and downstream actions such as withdrawals or refunds. Risk is no longer assessed at a single point in time, but across the sequence in which behaviour unfolds. This is what allows intervention before loss occurs, rather than after.
Event pipelines as the backbone
At the core of real-time monitoring is the event pipeline. Its role is not to make decisions, but to ensure that signals arrive fast, in order, and with enough context to be meaningful. In a well-designed streaming model, every relevant interaction is captured as it happens and enriched as it moves through the pipeline.
What matters here is not raw volume, but coherence. Events must be timestamped accurately, associated with the correct customer or entity, and made available to risk logic with minimal latency. Without this foundation, real-time monitoring collapses back into reactive alerting.
Features turn activity into signals
Raw events are not useful on their own. They become actionable only when transformed into features that describe behaviour. Features capture patterns such as velocity, repetition, deviation from baseline, or unusual sequencing. In streaming environments, these features are computed continuously, updating the system’s understanding of risk in near real time.
The critical difference from batch models is that features evolve dynamically. A login may be low risk in isolation, but when followed by rapid channel switching or a payout attempt, its significance changes. Streaming feature generation allows that shift in meaning to be recognised immediately.
Why entity resolution matters more in real time
Real-time monitoring breaks down quickly if the system cannot reliably understand who is acting. Entity resolution links events across devices, sessions, accounts, and identifiers to a single risk entity. In batch systems, inconsistencies can sometimes be corrected retrospectively. In streaming systems, mistakes propagate instantly.
Strong entity resolution ensures that:
- Behaviour is attributed to the correct customer or account
- Risk signals accumulate coherently across channels
- Controls are applied to the right entity, not the wrong one
This is particularly important in environments where fraud exploits fragmentation moving quickly across devices or accounts to stay below thresholds.
Regulatory alignment
The move toward continuous monitoring is consistent with the risk-based principles set out in international AML and financial crime guidance. Ongoing assessment, proportional response, and contextual understanding are all core elements of the framework articulated by the Financial Action Task Force, which emphasises that monitoring should reflect how risk actually materialises rather than relying on static checkpoints.
Automation Layers: Alert Suppression, Clustering, Typology Tagging, and Enrichment
Always-on monitoring dramatically increases signal volume. Every interaction, not just completed transactions can influence risk assessment. Without automation, this richness becomes noise. The purpose of automation layers is not to replace human judgement, but to ensure that human attention is spent where it adds the most value.
In real-time environments, automation determines whether monitoring scales intelligently or collapses under its own data weight.
Suppressing noise without blinding the system
Alert suppression is often misunderstood as “turning alerts off.” In practice, it is about recognising when additional alerts add no new information. Streaming models can identify patterns where repeated events confirm an already-known risk state and suppress redundant alerts accordingly.
This reduces analyst fatigue while preserving visibility into genuinely new or escalating behaviour. Suppression logic is dynamic, context-aware, and reversible unlike static alert thresholds that simply hide activity.
Clustering turns events into cases
Clustering groups related events into coherent narratives. Instead of producing dozens of alerts for the same underlying behaviour, real-time systems consolidate signals into a single evolving case. This makes risk easier to interpret and faster to act on.
Clustering is especially important when activity spans channels or time windows. What looks benign in isolation often becomes meaningful when viewed as part of a cluster. Automation ensures that these relationships are surfaced immediately, not reconstructed after the fact.
Typology tagging adds interpretability
Typology tagging assigns behavioural patterns to recognised risk scenarios. This does not require certainty; it provides context. Tagging allows systems to distinguish between different kinds of anomalies and respond proportionately.
For analysts and regulators alike, typologies create a shared language. They explain not just that something is risky, but how and why it resembles known patterns of concern.
Enrichment grounds decisions in context
Enrichment layers pull in additional context device attributes, historical behaviour, geographic consistency to refine decisions as they happen. In real time, enrichment must be fast and relevant. Excessive data adds latency; targeted data adds clarity.
The combination of suppression, clustering, tagging, and enrichment transforms raw activity into structured insight that can support immediate action.
Regulatory perspective
International AML guidance increasingly recognises that automation is necessary to manage volume and speed, provided it is governed appropriately. The Financial Action Task Force consistently emphasises that technology should support risk-based decisioning, transparency, and proportional response not obscure accountability.
Reducing False Positives Safely: Risk-Based Thresholds and Feedback Loops
Why false positives become more dangerous in real time
In batch monitoring, false positives are costly but survivable. Alerts can be reviewed later, transactions may still be reversible, and customer impact is delayed. In real-time environments, false positives carry a much higher price. A wrongly blocked transaction can interrupt a live customer journey, delay legitimate payouts, or trigger unnecessary escalation while funds are still in motion.
This is why simply lowering thresholds to “be safe” no longer works. In always-on monitoring, excessive sensitivity does not just waste analyst time it actively damages trust and conversion while offering diminishing risk reduction.
Risk-based thresholds instead of static sensitivity
The core shift is from uniform thresholds to risk-based tolerances. Rather than treating every transaction or event equally, real-time systems adjust sensitivity based on context: customer history, transaction type, channel, velocity, and potential impact.
This allows monitoring to be assertive where loss would be severe, and permissive where risk is limited and recoverable. Importantly, these adjustments happen continuously, not through manual rule changes applied after incidents occur.
Feedback loops turn decisions into learning
False-positive reduction does not come from better thresholds alone. It depends on structured feedback loops that allow the system to learn from outcomes. In real-time monitoring, feedback must be fast, reliable, and clearly attributed.
Effective feedback loops typically connect:
- Analyst decisions and overrides
- Confirmed fraud or non-fraud outcomes
- Downstream events such as chargebacks or complaints
What matters is not just that feedback exists, but that it flows back into both feature weighting and threshold calibration. Without this loop, real-time systems quickly drift back toward over-alerting.
Avoiding the compliance trap
One of the common fears around false-positive reduction is regulatory exposure, the idea that relaxing controls invites scrutiny. In practice, regulators focus less on raw alert volumes and more on whether controls are proportionate, risk-based, and explainable.
International AML standards consistently reinforce this principle. Guidance from the Financial Action Task Force frames effective monitoring as a balance between detection and proportionality, recognising that excessive false positives can be as damaging as missed risk when they undermine system credibility.
Key takeaway
Reducing false positives safely is not about being less cautious. It is about being more precise. Risk-based thresholds and fast feedback loops allow real-time monitoring to intervene decisively where it matters and stay out of the way where it doesn’t.
Signals That Matter in 2026: Why Context Beats Volume
In real-time transaction monitoring, the most important change is not the number of signals collected, but how selectively they are interpreted. Earlier monitoring systems treated signals as independent risk markers: device mismatch, IP change, unusual location, abnormal transaction size. Each signal carried weight on its own, often triggering alerts regardless of broader context. In 2026, this approach is widely recognised as counterproductive.
Modern risk engines treat signals as conditional. A device change means something very different when it occurs during routine account access than when it appears seconds before a high-value payout. Likewise, a new IP address may be irrelevant for a mobile-first user but highly anomalous for an account with historically stable access patterns. Signals do not indicate risk in isolation; they acquire meaning only when evaluated in sequence.
This is why device and IP intelligence has evolved from static fingerprinting into behavioural reference points. The question is no longer whether a device is new, but whether the way it is being used aligns with known behaviour. Real-time systems track interaction cadence, navigation flow, and response timing, allowing them to distinguish between legitimate variation and behavioural displacement.
Geolocation signals have undergone a similar shift. Geographic anomalies used to trigger immediate alerts, often producing large volumes of false positives in globally mobile user bases. In 2026, location is interpreted alongside velocity, session continuity, and channel transitions.
A sudden country change without behavioural disruption may be benign; the same change coupled with compressed timing and escalation toward payout carries far more weight.
Behavioural biometrics add another layer of discrimination. Patterns such as keystroke rhythm, gesture consistency, and interaction hesitation are not treated as definitive indicators, but as contextual modifiers. They help determine whether activity reflects genuine user intent or automated orchestration, particularly when combined with other signals rather than evaluated alone.
Perhaps the most significant evolution is the growing use of network-level patterns. Individual transactions may appear acceptable when viewed independently, but risk often emerges through relationships: shared devices, reused credentials, coordinated timing, or repeated interaction sequences across accounts. Real-time monitoring surfaces these patterns as they form, rather than reconstructing them after loss has occurred.
This selective use of signals aligns closely with international regulatory thinking. FATF guidance on risk-based monitoring explicitly supports the use of contextual, technology-driven indicators including device, IP, geographic, and behavioural data provided they are applied proportionately and with appropriate governance. The emphasis is not on collecting every possible signal, but on using relevant ones to understand how risk materialises in practice.
What distinguishes effective real-time monitoring in 2026 is restraint. Systems that surface fewer, better-interpreted signals consistently outperform those that flood analysts with raw indicators. Precision, not abundance, is what allows always-on monitoring to reduce false positives while still detecting genuinely harmful behaviour.
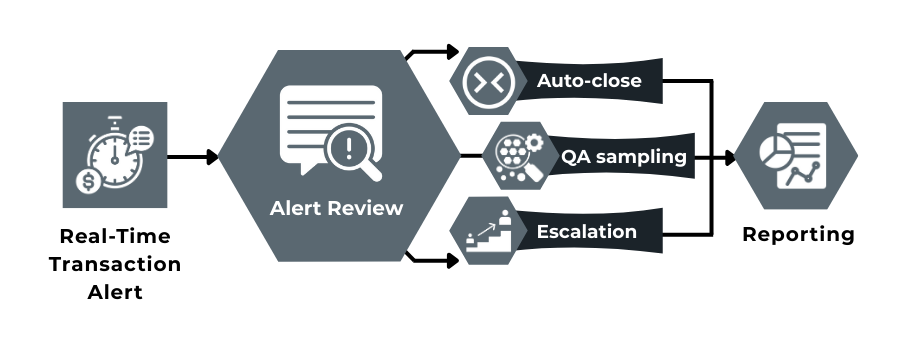
How to Operationalise Outcomes: Auto-Close Rules, QA Sampling, and Escalation Criteria
In real-time monitoring, alerts are not the product decisions. Streaming systems surface risk continuously, but without defined outcome pathways, they simply relocate friction from detection to review. By 2026, effective monitoring teams design outcome logic deliberately, ensuring that each alert resolves into a clear, auditable action.
Auto-close rules: removing noise without losing control
Auto-closure is the first operational layer where false positives are eliminated safely. It applies when additional review would not materially change the risk outcome.
Typical auto-close conditions include:
- Behaviour remains consistent with historical patterns
- Expected loss stays below defined tolerance
- Enrichment confirms low-risk context (device continuity, stable geo, normal timing)
Auto-closure does not mean invisibility. Each closed alert is logged with rationale, enabling later review and model tuning.
QA sampling: oversight without bottlenecks
Rather than reviewing everything, real-time teams rely on structured sampling to maintain control over automation. QA sampling shifts focus from alert presence to decision quality.
Sampling is typically applied across:
- Risk bands (low, medium, borderline)
- Decision types (auto-closed, friction-applied, escalated)
- Customer segments or corridors
This approach ensures automation remains accurate without recreating batch-era review volumes.
Escalation criteria: when human judgement is required
Escalation in always-on monitoring is driven by impact and trajectory, not alert count. A single event may justify escalation if it materially alters expected loss or indicates a shift in behaviour that automation is not designed to resolve.
Escalation criteria are usually tied to:
- Sudden increases in potential loss
- Behavioural breaks following sensitive actions (support contact, credential reset)
- Network-level signals indicating coordinated activity
Clear escalation rules protect analyst time while ensuring genuinely consequential cases receive attention.
Governance expectations
All three outcome layers must operate within a documented governance framework. International guidance makes clear that automation is acceptable even encouraged when firms can explain how decisions are made, reviewed, and adjusted over time. FATF’s risk-based approach explicitly supports proportional automation paired with accountability and auditability.
Key takeaway
Operationalising outcomes is about discipline, not speed. When auto-closure, sampling, and escalation are clearly defined, real-time monitoring scales without sacrificing control.
Governance: Model Drift, Periodic Tuning, Explainability, and Documentation
Real-time transaction monitoring changes not only how risk is detected, but how it must be governed. When decisions are made continuously rather than in batches, governance cannot rely on occasional reviews or static rule approvals. It becomes an ongoing discipline that ensures models remain aligned with risk appetite, regulatory expectations, and operational reality.
Model drift as a governance risk
In always-on environments, model drift is not an abstract technical concern; it is a business and compliance risk. Behaviour changes gradually, payment patterns evolve, and fraud adapts in response to controls.
Without active governance, models begin to reflect outdated assumptions, producing either blind spots or unnecessary friction.
What makes drift particularly challenging in real time is speed. Small degradations in performance can propagate quickly, affecting large volumes of transactions before they are noticed. Effective governance focuses less on preventing change and more on detecting when change becomes material. This requires continuous performance monitoring tied to expected outcomes, not just alert volumes.
Periodic tuning without constant interference
A common mistake in streaming environments is over-tuning. When models are adjusted too frequently in response to short-term fluctuations, stability is lost and explainability suffers. Good governance draws a clear line between monitoring and intervening.
Periodic tuning creates space for evidence to accumulate. It allows teams to distinguish between noise and signal, seasonal variation and genuine drift. Rather than reacting to every deviation, governance frameworks define when intervention is justified and who has authority to make it. This restraint is essential to maintaining confidence in automated decisions.
Explainability as regulatory currency
As monitoring becomes more sophisticated, the burden of explanation increases. Regulators and partners are less concerned with the mathematical elegance of a model than with its practical impact. They want to know why a decision was made, whether it was proportionate, and how it aligns with stated policies.
Explainability in real-time systems is achieved through clear linkage between signals, context, and outcomes. Decisions should be traceable to understandable factors, and those factors should remain consistent over time. This does not mean exposing every technical detail, but it does mean being able to articulate the logic behind decisions in human terms.
Documentation as living infrastructure
In batch-era monitoring, documentation often lagged behind implementation. In always-on systems, that lag becomes a liability. Documentation must evolve alongside models, thresholds, and outcome logic. It serves not only auditors, but internal teams who rely on shared understanding to operate effectively.
Well-governed monitoring functions treat documentation as infrastructure rather than paperwork. It records assumptions, defines responsibilities, and captures the rationale behind changes. This continuity is what allows organisations to scale monitoring without losing control or credibility.
These governance principles align closely with international expectations around risk-based monitoring. Guidance from the Financial Action Task Force consistently emphasises ongoing assessment, proportional controls, and accountability when technology is used to support AML and financial crime objectives.
KPIs: Alert-to-Case Ratio, Analyst Hours per 1k Transactions, True-Positive Yield, Time-to-File
The shift to real-time transaction monitoring fundamentally changes how performance should be measured. Legacy KPIs were built for batch environments, where alerts accumulated slowly and review timelines were forgiving. In always-on monitoring, those metrics quickly become misleading. What matters is not how many alerts are generated, but how efficiently risk is converted into defensible outcomes.
One of the most revealing indicators is the alert-to-case ratio. In batch systems, high alert volumes were often tolerated as a cost of coverage. In real-time environments, a high ratio usually signals poor signal quality or ineffective suppression logic. Mature monitoring programmes aim for alerts that already resemble cases meaning context, enrichment, and clustering have done most of the work before an analyst ever intervenes.
Closely related is analyst hours per 1,000 transactions, which captures the true operational cost of monitoring. Always-on systems are designed to absorb growth without linear increases in headcount. When this metric trends upward, it is rarely because risk has increased proportionally; it is usually a sign that automation layers or outcome routing are misaligned. This KPI forces organisations to confront whether real-time monitoring is actually scaling as intended.
Accuracy comes into focus through true-positive yield. In real-time monitoring, yield matters more than raw detection counts. A system that identifies fewer cases but with higher confidence is more valuable than one that overwhelms teams with marginal alerts. True-positive yield reflects whether signals, thresholds, and feedback loops are working together to surface genuinely meaningful risk.
Finally, time-to-file measures how quickly an organisation can move from detection to regulatory action when required. In jurisdictions with strict reporting timelines, delays introduce compliance exposure even when detection is timely. Real-time monitoring compresses the front end of this process, but only disciplined operational design ensures that downstream steps keep pace.
Regulators increasingly expect firms to demonstrate not just that monitoring exists, but that it is effective and proportionate. UK supervisory guidance consistently emphasises operational effectiveness, timely escalation, and the ability to evidence outcomes not simply alert generation.
Key takeaway
In real-time environments, KPIs are no longer about volume. They are about efficiency, accuracy, and speed. The right metrics reveal whether always-on monitoring is delivering better decisions or simply faster noise.
Conclusion
By 2026, real-time transaction monitoring is no longer defined by how many alerts a system can generate, but by how effectively it can decide. Batch-era monitoring was built for a world where time existed between action and consequence. That gap has disappeared. Money now moves at the speed of intent, and risk management must move with it.
Always-on monitoring succeeds because it aligns risk assessment with how behaviour actually unfolds. Streaming architectures, contextual signals, automation layers, and adaptive thresholds allow systems to intervene precisely early enough to prevent loss, and selectively enough to avoid unnecessary friction. The result is not just better compliance outcomes, but more resilient payment operations.
What distinguishes leading organisations is not the sophistication of their models alone, but the discipline of their operating design. When outcomes are clearly defined, automation is governed, and performance is measured through meaningful KPIs, monitoring becomes predictable rather than reactive. False positives fall not because controls are weakened, but because decisioning becomes more intelligent.
Crucially, governance has moved to the centre of this shift. In real-time environments, trust is built through explainability, documentation, and evidence that systems behave consistently over time. Regulators, partners, and customers alike expect monitoring to be proportional, accountable, and aligned with stated risk appetite. Always-on monitoring meets those expectations only when it is treated as infrastructure, not tooling.
As payment rails continue to accelerate, the gap between batch monitoring and real-time decisioning will only widen. Organisations that cling to delayed alerting will find themselves absorbing unnecessary loss, friction, and operational cost. Those that invest in always-on monitoring will gain something far more valuable: the ability to grow at speed without losing control.
In 2026, that capability is no longer optional. It is a competitive advantage.
FAQs
1. Why does batch transaction monitoring fail in real-time payment environments?
Batch monitoring was designed for delayed settlement and reversibility. In real-time rails, funds move instantly, so alerts raised hours later no longer prevent loss. Always-on monitoring evaluates risk while behaviour is unfolding, not after outcomes are final.
2. What is the difference between real-time monitoring and real-time decisioning?
Real-time monitoring observes events continuously, while real-time decisioning acts on those observations immediately. Monitoring without decisioning still creates delay; decisioning without monitoring lacks context. Effective systems combine both.
3. How does streaming monitoring reduce false positives?
By evaluating behaviour across sequences of events rather than isolated transactions. Contextual interpretation, suppression logic, and feedback loops allow systems to intervene only when risk meaningfully escalates.
4. Are behavioural and device signals acceptable under AML regulations?
Yes, when used proportionately and with governance. International standards support contextual signals such as device, IP, and behavioural patterns provided decisions are explainable and aligned with risk-based principles.
5. What role does automation play in real-time transaction monitoring?
Automation ensures scale. It suppresses redundant alerts, clusters related activity, enriches context, and routes outcomes efficiently allowing human analysts to focus on genuinely high-impact cases.
6. How do firms maintain control when alerts are auto-closed?
Through QA sampling, audit trails, and documented decision logic. Auto-closure removes noise, not accountability. Outcomes remain reviewable and tunable over time.
7. What KPIs indicate a healthy real-time monitoring programme?
Key indicators include alert-to-case ratio, analyst hours per 1,000 transactions, true-positive yield, and time-to-file. These metrics show whether monitoring is efficient, accurate, and scalable.
8. Is always-on monitoring only about compliance?
No. While it strengthens compliance, its real value lies in reducing friction, improving customer experience, and enabling growth on real-time payment rails without proportional increases in risk or cost.